During our meetings one of our favorite topics has been a board game
recommendation system. The goal would be to have board game experts
use their vast knowledge of which games are worth playing to point new
and old players to games that fit their immediate requirements.
1. The Problem
The Columbus Area Boarding Society
(CABS) has over 1000 board games. We aim to save them from the
paralysis of choice such a large collection brings. At any given hour
of a meeting, dozens of players will mill around in front of the
library’s game cabinets and waste time not playing games.
Each group of people has various restrictions on what they will
eventually pick. Major requirements are often the Number of Players
and the Length of Gameplay. A group of 3 people is not interested in
playing a game for 12. Likewise, a group with only an hour available
is not interested in anything taking 4 hours.
Other requirements are more varied. Genre, categorization, game
mechanics, publishing date, suggested age, or community
awards. Veteran board gamers will take all these things into
consideration in varying amounts when choosing a new game. This
analysis is very much an art, not a science. We aim to automate their
expertise build a system to take any or all of these factors into
consideration for everyone, not just experienced players.
2. Expert Sources
Unfortunately, even experts can make mistakes. A single expert might
not have all the knowledge necessary to make a good recommendation. We
will use our local experts at CABS to test and refine the system. With
their experience at our disposal, we can find the correct calibration
settings for how much weight we should give to qualities described
above. Pooling their collective expertise we will be able to cover a
wide range of games and their appropriate pairings.
We also have BoardGameGeek.com (BGG),
the single largest website covering the board gaming community. BGG
has a free API we
can access to download the extensive board game data. Using this, we
can import thousands of games worth of data into our database,
allowing us to focus our time on tweaking our recommendation system as
tightly as possible.
3. Our Motivation
We are going to integrate with the CABS library system so that we can
allow members to use our system on a day to day basis. This will
provide real value to a local community organization and its
members. We hope to be able to use the data collected from actual
usage to further tweak the system into a mind-reading, board game
recommending machine.
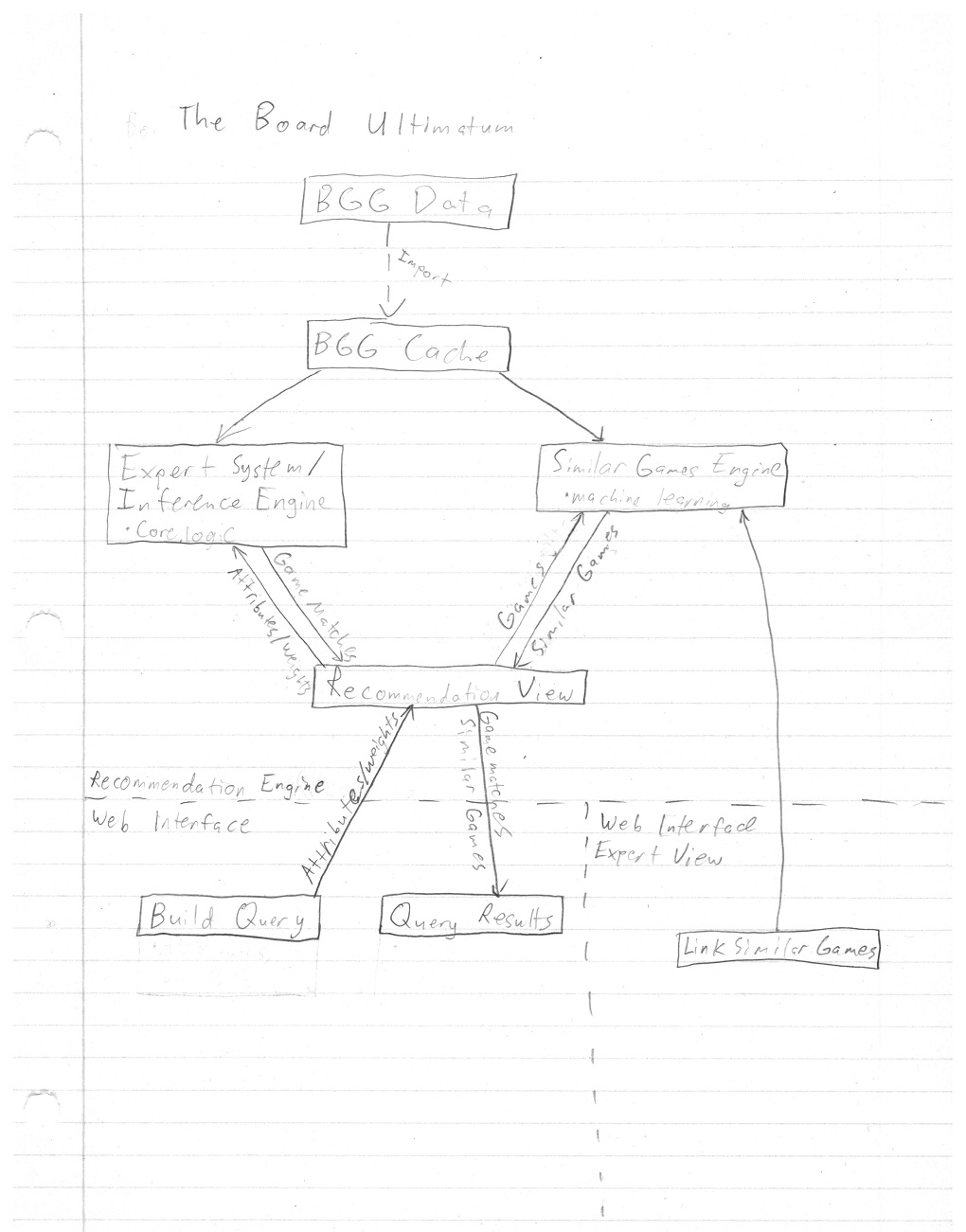
4. Details
Interfaces
These are two separate interfaces for the two ideas. The Expert
Weighted Query System is of more immediate value to the users of the
system. The system would be much useful very quickly and very
extendable. The User Profile approach would be very similar to a
Netflix style recommendation engine. The amount of work required for
this is much greater with no guarantee of it providing valuable
output. Team members have expressed interest in this approach and we
will attempt it given time.
Expert Weighted Query System:
The users will primarily access the system through a web interface
built by the team. This will prompt them to enter the primary
information necessary for the recommendation engine to make a
decision. To begin, these will be Number of Players and Game
Length. We will add the ability to enter other information such as
categories or game mechanics as the engine begins to handle
them.
There will be a select box with an appropriate set of time
ranges (<20m, 30m, 45m, 1h, 1.5h, 2h, 3h, 4+h). There will be a
multi-select box for number of players (1,2,3,4,5,6, 7+). When we add
features such as Game Mechanics, we will allow a multiple tag
selection. This will likely be auto-completed through a query
interface, but this has not been finalized. After submitting the form,
the recommendation list is shown in a ranked order. Relevant
information, pictures, and links to BGG are shown.
User Profile Driven Recommendations:
An stretch goal for the project will be to use user profiles to track
and learn which games each user likes. The CABS system has the
capability to track each user’s checkouts and BGG has user profiles
with tracked plays and collections. The interface for this page would
allow the user to enter the players involved in the proposed group and
recommend games the players are all known to like.
Players will be able to type in the names of a player into a text
field, with known players being auto-completed. Optionally, we can
integrate with the bar code scanner device already employed by CABS,
capable of scanning the membership badges. After a player is added,
another text field will appear, ready to add another player. After
submitting the form, the recommendation list for this particular group
of players is shown.
New players will be able to be added to the system and linked with
their BBG user account.
Data
The BoardGameGeek
API will provide us
with much of the initial data we will need. We will automate the
process of gathering data and keeping it updated in our own database
through regular resynchronization. We require a local copy of the data
as the CABS meeting location does not have regular internet access. We
will run a copy of the server locally on the machine setup to handle
checkouts.
This is a sample API
response from
the BGG API. The basic game information (Name, BGG ID, Publisher, Designer,
Date Published) and categorization data (Number of Players, Game
Length, BGG Rank, Game Mechanics, Age Limits, etc) are included. In
addition to detailed game information, we can gather data about User
Collections, and Recorded User Plays. Such information may prove
useful if we are able to attempt the User Profile system.
This this information available, we will be able to focus on
leveraging our experts’ judgement for the recommendation engine
instead of inputing data.
Recommendation Engine
The meat of the project will be to accurately recommend games based on
the user desires. Unfortunately this is still the most undecided
aspect of the project. We are not entirely sure of the best approach
and these are primary ideas.
We will begin this in phases.
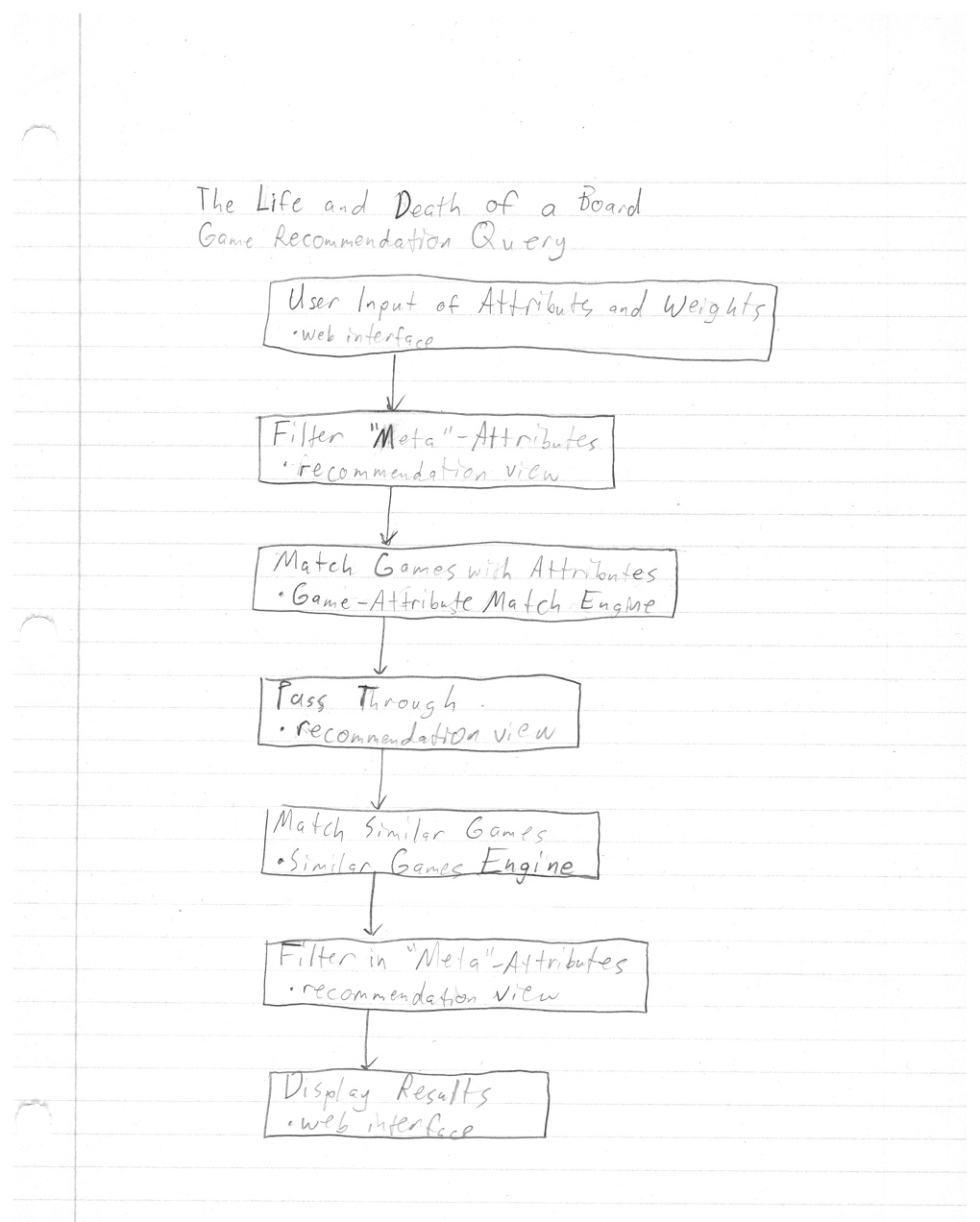
1. System Integration: Recommend Anything
The first step is to hook up a system that accesses the data retrieved
from BGG and return a set of recommended games to the user regardless
of accuracy. The games recommended is not important, but making the
entire system work together as a coheisive whole is
important. Parallel work on downloading BGG data and setting up an
initial interface will be done during this step.
2. Number of Players and Game Length
Now that we have some amount of data from BGG, we can begin to
restrict our recommendations to games which match the user’s
restrictions of Players and Time. Any games matching the appropriate
number of players will be considered. Next, we look for overlapping
time ranges in the board game data and the user’s selection. This
step is essential in providing a quality recommendation to the
user. Games not fitting these parameters will not be a useful
recommendation in the near term. At this step however, the actual
quality of the game is not being considered.
3. Weight by BGG Rank
BGG provides a highly trusted ranking system. The overall rankings and
the general consensus of quality (ie. fun) seem to be well
correlated. As an initial quality filter, we will weight the
recommendations based upon these rankings. We now have games the users
have time and people to play presented with some emphasis on high
quality.
4. Associate Related Games by Expert Review
This piece is going to be essential to the performance of the
system. Our interviews with our experts will provide us with essential
guidance to identify which qualities in games are related.
Exactly how we integrate our expert advice into the system is still up
in the air. We have talked about using a simple rule based
system. Once the experts provide some rules, we could use them to add
weights to certain types of games in certain situations.
5. Neural Network Linking
We have discussed having our experts train a neural network which
learns which games are similar. When it knows which games are similar,
it could use the rules developed in Step 4 to also recommend similar
games to their specific recommendations.
6. Weight by BGG Categorization & Mechanics
Lastly, we would like to identify a useful way to recommend games
based on certain Mechanics or by a whole Category. If the user selects
“Economic Game” as a Category, we should appropriately weight the
recommendations based on this Category. However, we may not want to
simply eliminate other games from the recommendations list, as similar
games may still be relevant but lacking the exact categorization. We
are considering running some clustering algorithms on the database of
games, scored by how the experts rank them as similar. If a pair of
games is scored extremely similar by the experts, but has a slightly
different set of tags, we still may want to recommend both when the
user enters one of the set of tags.
7. User Profiles
Beyond this, we have discussed mining the BGG Board Game Collections
data and the Board Game Plays data to draw conclusions about which
games a given set of players will like.