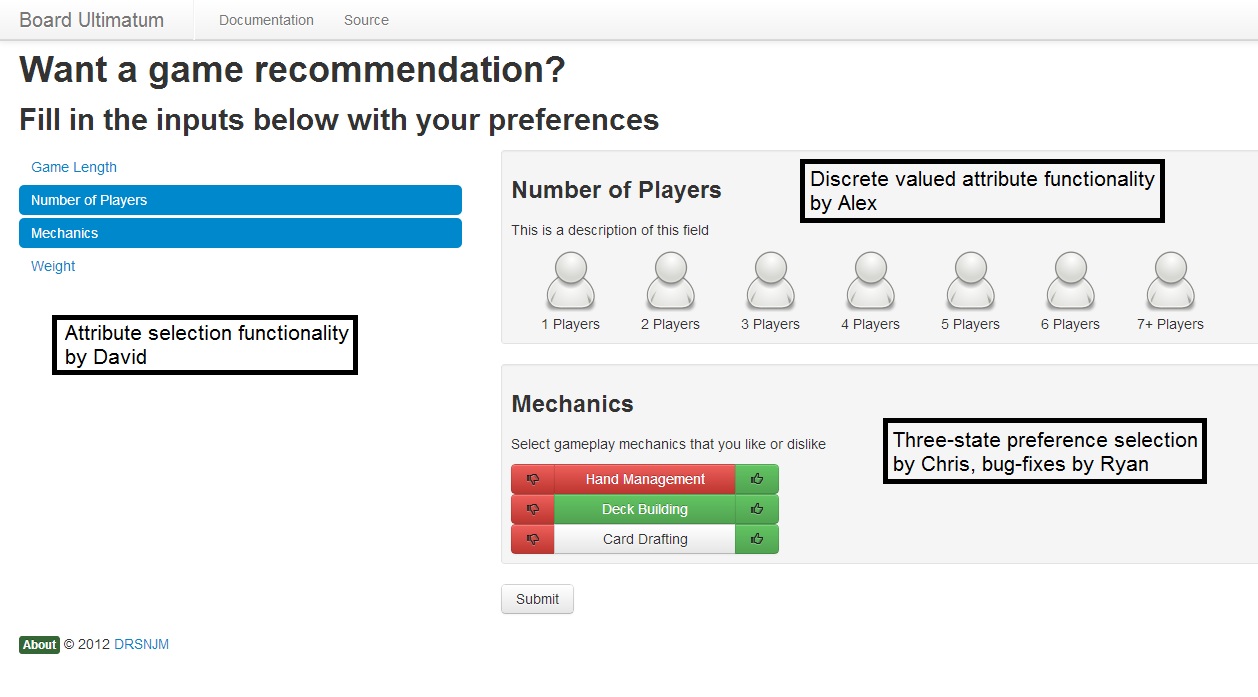
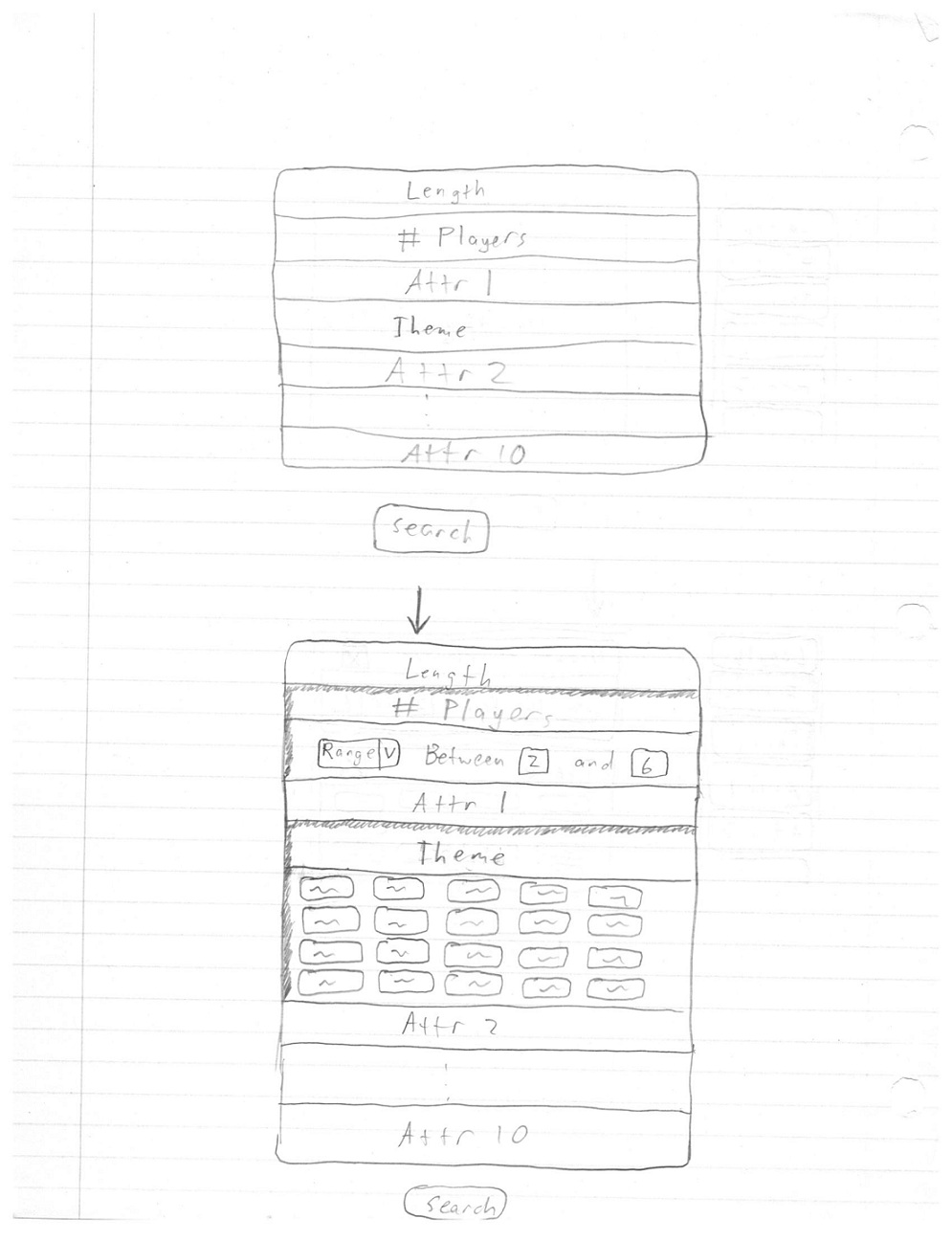
In the context our project, we would like to extend our project to not only
provide games directly based on a user’s preferences, but also further recommend
games that are similar to the ones provided by our rule-based system. However, a
challenge arises when we try to define the term “similar.” How do we know that a
user will like a game that is similar in attributes to another? What makes
certain types of games desirable if a user liked one particular game? To
alleviate this problem, we decided that utilizing some sort of clustering,
categorization, or machine learning technique would be beneficial.
To start with the most basic of techniques, first we need to numerically
represent our knowledge base. This would need to be in the format of a vector:
< a1, a2, a3, a4 … an >
Where an is the numerical representation of some attribute of the game. For
example, a1 may be the minimum number of players and a3 may be the number of
minutes a game typically takes to play. One metric of game similarity would be
the euclidean distance between the two vectors.
Minimizing distance would yield the two games that are most numerically similar
to each other. To query such a system quickly, a data structure such as an
octree or k-d tree could be used. It is also worthwhile to note that since each
an would cover a different domain, it would be necessary to normalize each
domain to a range of values such as (0.0, 1.0). Otherwise, attributes
represented with large numeric domains would have a greater impact on the
euclidean distance. This issues leads us into our next line of thought,
weighting different attributes by their importance to the user.
One way of introducing importance into this equation is to add an additional
constant to each attribute of the game, in this case cn, where cn is some value
in the range (0.0, 1.0).
< c1*a1, c2*a2, c3*a3, c4*a4 … cn*an >
A cn value of 0 represents the least importance, as it makes the nth attribute
have a value of 0 for all vectors. Conversely, a value of 1 represents the
greatest importance to the user, as it allows that attribute to have the largest
impact on the resulting distance.
An alternative method of achieving an “importance” when comparing attribute
values is with gaussian curves. In this case, with the curve centered at μ = an,
some value would be chosen (for example .75) and all values where curve is
greater than .75 for each an would be accepted as “similar.” To introduce the
idea of importance, σ can be changed for each n. A low σ results in a very
narrow curve, and thusly a very narrow range of “similar” values in that axis,
representing high importance, whereas a large σ results in a very wide range of
values, representing a low importance.
In order for this method to work as intended, the curve would have to be scaled
by a factor of σ such that the peak was always at a value of 1.0.
This method could also potentially be used for determining the “similarity”
space for a set of multiple vectors (such as a user’s previously enjoyed games),
but more on that later.
While these methods may be very effective for finding games that are very
similar in terms of their attributes, however, much of what users desire
involves variety in games. If the only recommendations made are games that are
nearly identical, will the user benefit? Also, are there intangible factors that
make games recommendable in relation to other games that are hard to represent
numerically or via a set of rules? One solution to this issue is to use a
machine learning system.
With a machine learning system, the experts themselves can train the system to
identify games that would be appropriate for recommendation. The hope being that
with enough input, the system itself will produce results similar to that of an
expert. This may be accomplished through, for example, a neural network. First,
the expert would be given an interface that would randomly, or at the choosing
of the expert, provide two games; let’s call them Game A and Game B. The expert
would choose, via some sort of slider UI element a value, with “Would never
recommend” on one end of the spectrum and “Would highly recommend” on the other.
This would be in reference to if the user enjoyed Game A considerably, the
expert would “highly recommend” Game B to that user. The input pattern to the
neural network would be the union of the two games’ attributes, such as the
following:
< a1, a2, a3, a4 … an, b1, b2, b3, b4 … bn >
The network would then be trained with the output being a single floating point
value, with 0 corresponding to “never recommend” and 1.0 corresponding to
“highly recommend.” Once a sufficient amount of training data had been provided,
the system should hypothetically be able to return a confidence factor, provided
with two games, of whether if the user enjoyed the first, they would also enjoy
the second.
The problem with this method lies in the performance of the system. If a certain
number of recommendations are to be made, it would be preferable that those
recommendations have the highest output from the neural network. This means that
in order to arbitrarily find the best match, the entire dataset has to be fed
through the network. If a large dataset exists, this will be very inefficient. A
possible solution to this problem is to have a process running in the
background, updating a sorted set of values for each vector with the output of
the network using some sort of a caching system such as Memcached or Redis for
storage. This way, the best results can be pulled quickly from the cache.
It would be necessary to also keep a database of the experts’ training data.
This way, the network can be trained over as many epochs as necessary. This
would also allow for different networks to be tested and trained with various
architectural choices such as varying numbers of layers and learning rates. The
training data could also be used for some other type of machine learning device,
such as a Support Vector Machine.