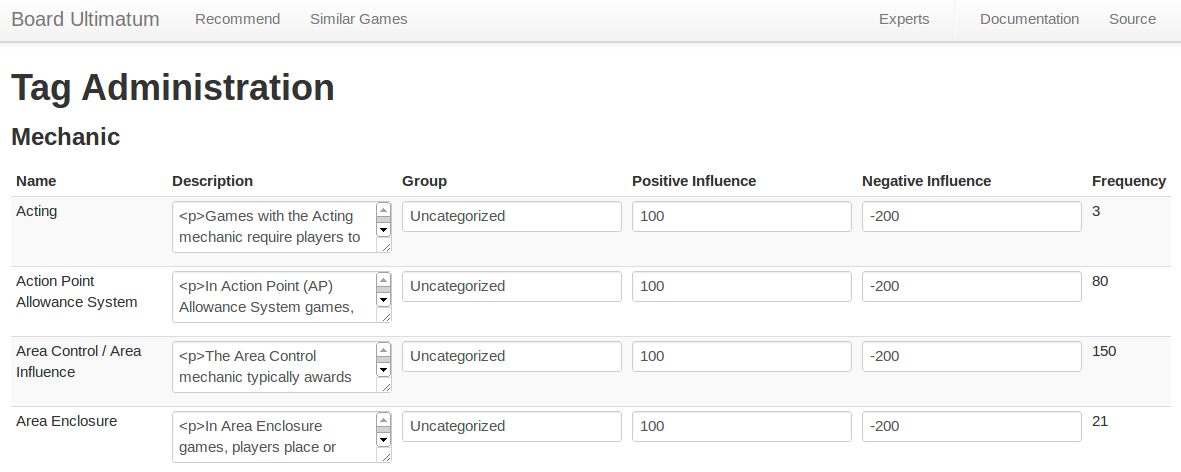
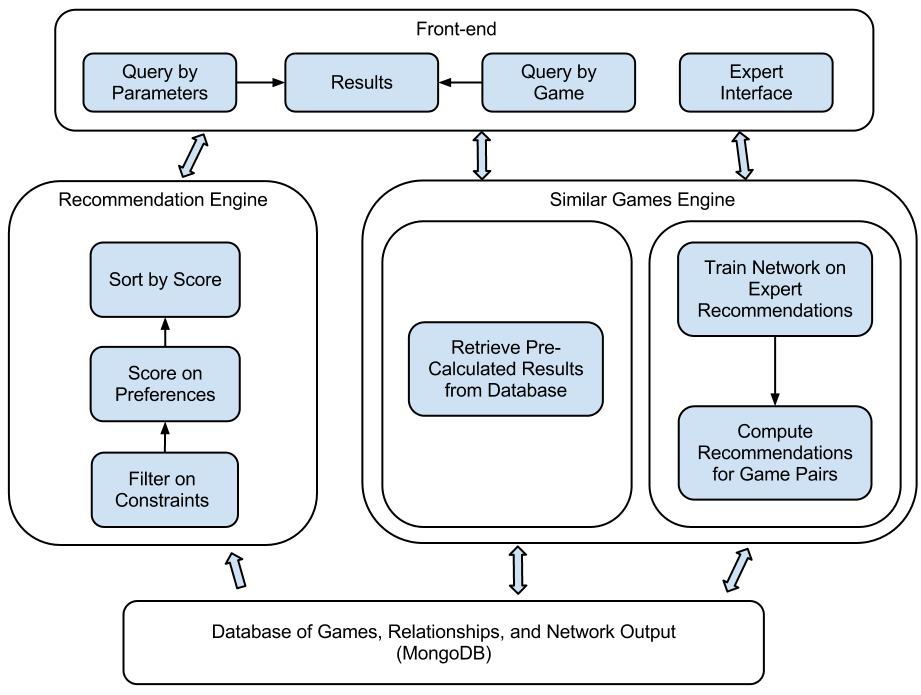
Neural Network Approach
After training the neural network on approximately 200 training samples, it was evident that the network did not necessarily generalize to games outside of the scope of the ones rated by experts in the training set. Further input will be necessary to continue to complete the model; this will hopefully be completed in the coming weeks as Alex makes more vists to CABS meetings. Once a better picture of the training data develops, the network should hypothetically generalize better to the regions of the input space that do not perform well at this point in time (for instance, war games.) This portion of the project will continue to be a work in progress. In the mean time, as seen in our progress reports, I have also set up an alternate method to provide users with a very literal correlation of similarity between games.
Simple Statistical Approach
In order to provide results that were more relevant in the immediate context of publicizing our project, I introduced an alternate method to the neural network approach that backtracks to some of the work that I had done earlier in the project. Rather than train an network with the training data, the stats method performs component analysis to return a 10 dimensional vector for each game. The confidence level for each game relative to the other games is then calculated merely from the euclidean distance between the two vectors.
Drawbacks
While this method provides games that are numerically similar to each other, often returning different versions of the same title in the search results, it fails to meet our initial goal of providing users with recommendations based on the more esoteric relationships with games. While two games, by their attributes, may be incredibly similar, they may be a poor recommendation, particularly if the user is looking for variety and new options in the games that they are playing. It is for these reasons that, while we are leaving this method as an option, we would much prefer the neural net approach to be used and to be successful in providing users with a diverse listing of similar games.